
VMware Admission Control
Admission Control özelliği birçok kez yanlış anlaşılmaktadır bunun sebeplerinden biri özelliğin defaultta kapalı gelmesi ve dikkat edilmemesidir. Aslında birçok ortamda vSphere HA’in sağlıklı çalışması için atlanmaması gereken Admission Control özelliğini bu makalede sizlere detaylı şekilde açıklayacağım.
vCenter Server’da cluster seviyesinde HA açıkken ayarlayabildiğimiz Admission Control ile failover anında cluster’da aktif durumda olan host’ların fail olan host üzerindeki sanal makineleri kendi üzerinde alarak çalıştırabileceği yani yeterli kaynağa sahip olmasından emin olmak amacıyla Admission Control kullanırız.
Admission Control sistem yöneticilerine seçmeleri için 3 farkı algoritma ile gelmektedir. Her algoritmanın avantajları ve dezavantajları bulunmaktadır. Bu algoritmaları tek tek inceleyelim.
1.Cluster Resource Percentage Algorithm
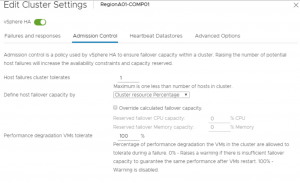
En fazla tercih edilen algoritmadır bu durumu kolay konfigure edilmesine ve esnekliğine bağlayabiliriz. Yukarıdaki ekran alıntısında görüldüğü gibi CPU ve Memory bazında hostlarda failover anında kullanılması için yüzde olarak rezervasyon yapılabilmektedir. Fakat bu özellik vSphere 6.5 ile değişmiş ve yüzde girilme zorunluluğu ortadan kaldırılmıştır. Basitçe clusterda bulunan hostlardan failover durumu oluşmasında kaç host’un tolere edilmesi belirtilebilir. Tolere edilmesi gereken host sayısını yazdığınızda yüzde otomatik olarak sistem tarafından hesaplanmaktadır. Bazı durumlarda CPU ve Memory yüzdesi eşit tutulmak istenebilir bu sebeple otomatik olarak ayarlanmış yüzdeyi override edebilir değişiklik uygulayabilirsiniz.
Yüzde olarak girilmesinden çok tolere edilmesi talep edilen host sayısını girmek daha avantajlıdır. Cluster’a bir host daha eklenmesi durumunda HA tarafından yüzde tekrar hesaplanmakta ve rezerve edilen alan değişmektedir. vSphere 6.5 öncesinde bu işlem manuel olarak admin tarafından yüzdeyi değiştirerek yapılmaktaydı.
2.Slot Size Algorithm
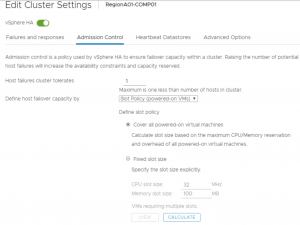
Host Failures Cluster Tolerates olarak da bilinen bu algoritma diğerlerine nazaran en eski ve komplex olanıdır. Cluster Resource Percentage Algoritmasında olduğu gibi fail anında tolere edilmesini istediğimiz host sayısını girebiliriz.
Slot cluster’daki her power on durumdaki sanal makineler için rezervasyon gereksinimlerini sağlayacak şekilde memory ve CPU kaynaklarının mantıksal olarak tanımlanmasıdır. Evet karışık bir tanım fakat kısaca slot en kötü senaryodaki CPU ve memory reservasyon gereksinimidir.
vSphere HA clusterdaki en yüksek tanımlanmış CPU ve memory rezervasyonunu baz alarak slot size tanımlar. Eğer 32Mhz üzeri CPU rezervasyonu tanımlanmamışsa HA default değer olan 32Mhz’i kullanır. Eğer memory rezervasyon tanımlanmamışsa HA default 0MB + Memory overhead olarak tanımlama yapar.
Örnekleyerek açıklayacak olursak clusterda bulunan 2 sanal makine için ilk sanal makinede 4Ghz CPU rezervasyonu 16GB memory rezervasyonu olduğunu düşünelim ikinci sanal makinede 2Ghz CPU rezervasyonu ve 32 GB memory rezervasyonu bulunsun. Bu durumda CPU için slot size 4Ghz ve memory için slot size 32GB + memory overhead olacaktır.
Bu algoritmanın kullanıldığı clusterlarda VM bazlı rezervasyon yapma konusu önem arz etmektedir. Gerekmediği durumlarda yapılması önerilmemektedir veya Resource Pool bazlı rezervasyonlar önerilmektedir.
Slot size hesaplamasında en kötü senaryonun ele alındığını gördük. Diğer bir durum cluster’da bulunan uygun slot sayısını hesaplamak olacaktır. Hesap aslında çok basit bir host için kullanılabilir CPU yu CPU slot size’a böleceğiz ve kullanılabilir memory’i memory slot size’a böleceğiz. Bu işlem bize bir host için hem memory hem cpu bazında slot sayısı verecektir. Peki memory ve CPU arasında slot farkı ne olacak? Örneğin 10 CPU slot hesapladınız fakat 4 memory slot blunuyor. Bu durumda host’ta kullanılabilir slot sayısı 4 olacaktır.
Peki clusterdaki slot sayısını Vmware tarafından görüntüleyebilir miyiz? Cluster bazında Monitor diyerek HA tabı altında Advanced Runtime Info kullarak slot size bilgisine ulaşabilirsiniz.
Fixed Slot Size seçeneği ile CPU ve Memory slot size’larını kendiniz tanımlayabilirsiniz. Bu durumda birden fazla slot gerektiren sanal makinelerin bilgisi göz önünde bulundurulması için HA tarafından tepsit edilip kullanıcıya arayüzde gösterilebilmektedir.
3.Failover Hosts
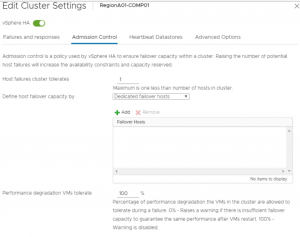
Üçüncü ve son algoritmamızda hot standby olarak da tanımlanan hazırda failover anı için boş bekletilen host veya hostlar seçilebilmektedir. Aşağıda görüldüğü gibi listeye eklenen hostlar üzerinde DRS’in bir parçası olamamakta ve manual olarak dahi VM power on edilememektedir.
vSphere HA failover anında sanal makineleri power on etmek için bu listedeki hostları öncelikli olarak kullanacaktır. Başarısız olması halinde clusterda bulunan diğer hostlara yönelecektir.
Bütün algoritmalarda geçerli olan bazı durumla HA’in failover yapmasını etkileyecektir. Örneğin VM to Host Rule ve benzeri rule’lar yazarak ilgili sanal makinelerin farklı hostlarda çalıştırılması kısıtlanabilmektedir. Bu durum HA’in fail olan sanal makineyi farklı bir host’ta restart etmesini engelleyecektir. Bu gibi durumların incelenmesi neden makinenin restart olmadığını ögrenmek için clusterdaki master host’un fdm logları detaylı olarak incelenmelidir.
Performance Degradation

Admission Control ile failover durumunda sanal makinelerin power on edilebileceği kullanılabilir hostların bulunmasını garanti edebileceğimiz öğrendik. Peki restart sonrası sanal makilere kalan kaynak yeterli olacak mı?
vSphere 6.5 ile gelen Performance Degradation yani performans kaybı özelliği ile yüzde kaç performans kaybı tolere edilebileceği belirtilebilmektedir. Default olarak değer %100 gelmektedir. Fakat bu değeri yüzde 25 olarak değiştirebilirsiniz bu ortama ve SLA’e göre değişiklik gösterebilir. Fakat değeri %100 olarak bırakmak uyarıyı etkinsizleştirmek yani performans kaybını göze almak anlamına gelmektedir.
Bu durumu örnekle açıklayacak olursak, 100GB memory’ye sahip 4 host’tan oluşan bir cluster düşünelim. Admission Control aktif edilerek 1 host’u tolere edicek şekilde Cluster Resource Percentage Algoritması kullanılmıştır. Yani 100GB – 25GB = 75GB kullanım clusterda uygun görülmektedir. Fakat 80GB memory aktif olarak kullanılabilir. Bu durumda bir karar verilmesi gerekiyor. Performans kaybı göze alınacak mı veya ortama yeni bir host eklenecek mi?